Simulation data offers a fast, scalable way to train autonomous vehicles, but current efforts are falling short in translating virtual testing into real-world performance. As the industry strives to better integrate real-world driving complexities into simulation, it must bridge this gap to unlock AVs' full commercial potential.
Autonomous vehicle development hinges on the effective use of mileage data, spanning simulation, supervised, and driverless categories. This foundational overview explores how these data types contribute to AV testing and validation, setting the stage for future discussions on the challenges and opportunities in the industry.
This post draws parallels between genetic diversity in biology and model collapse in AI, highlighting how both systems rely on diversity to avoid degradation and maintain robustness. By understanding these analogies, we can develop strategies to prevent AI model collapse and build more resilient, fair, and sustainable AI systems.
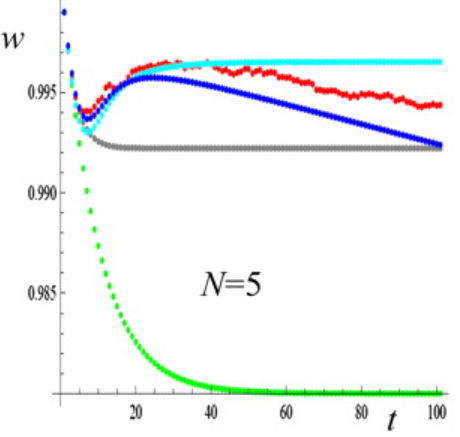
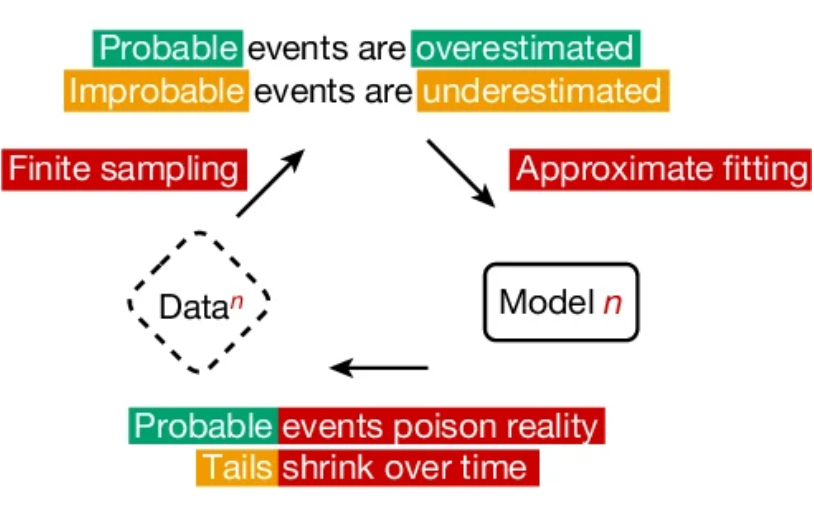
This post examines the theoretical risk of model collapse in AI, focusing on a study by Shumailov et al. that explores a worst-case scenario where excessive synthetic data degrades model performance. While this issue is not currently prevalent in LLMs, the study provides insights into how over-reliance on synthetic data could potentially lead to reduced data diversity and accuracy in the future.
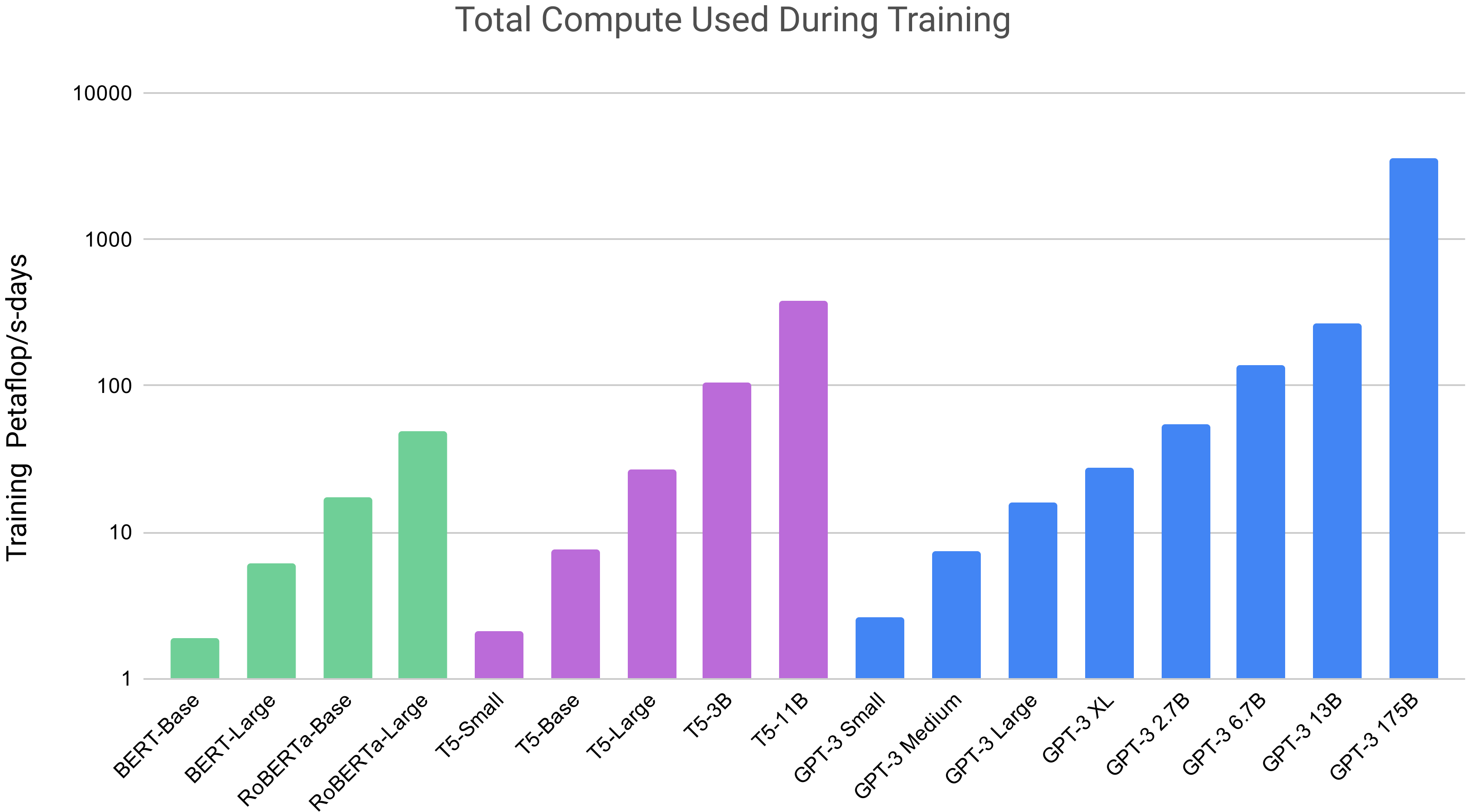
This post explores the substantial compute and energy requirements of LLMs, focusing on Chat GPT-3. It details how increasing model parameters significantly raises the demand for computational power, exemplified by the usage of petaflop/s-days. The post also compares these requirements to the capabilities and energy consumption of the world's fastest supercomputer, Frontier, to highlight the scale of resources involved.
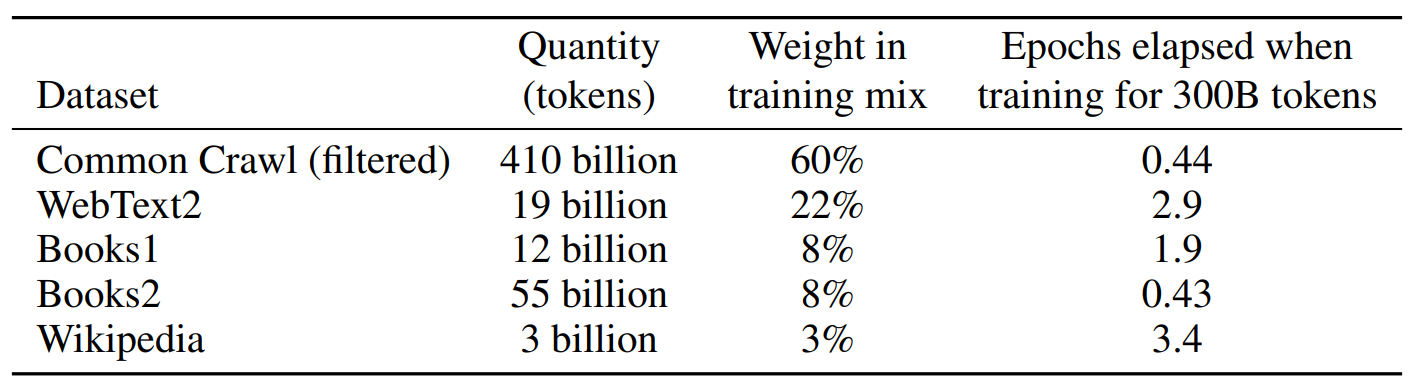
Data quality plays a crucial role in training large language models like GPT-3. This post delves into the decisions made by OpenAI to optimize data for GPT-3's training, from filtering vast datasets to incorporating high-quality sources. It highlights how a combination of Wikipedia, WebText2, Books1, and other curated data was essential for achieving superior model performance. Learn about the importance of data quality and the strategies used to enhance LLM training.
This post examines the extensive data sources used in training large language models (LLMs), such as web pages, digitized books, and scholarly articles. It provides an in-depth analysis of the estimated amounts of text data available and discusses how models like GPT-3 utilize only a small fraction of this data. The focus is on understanding how much additional data is available as models continue to exponentially grow in size.
TPM teams can be a great value add for any organization that has technical cross-functional programs. However, they can also become bloated and ineffective if not structured correctly. Here we look at the need for TPM teams to be centralized.
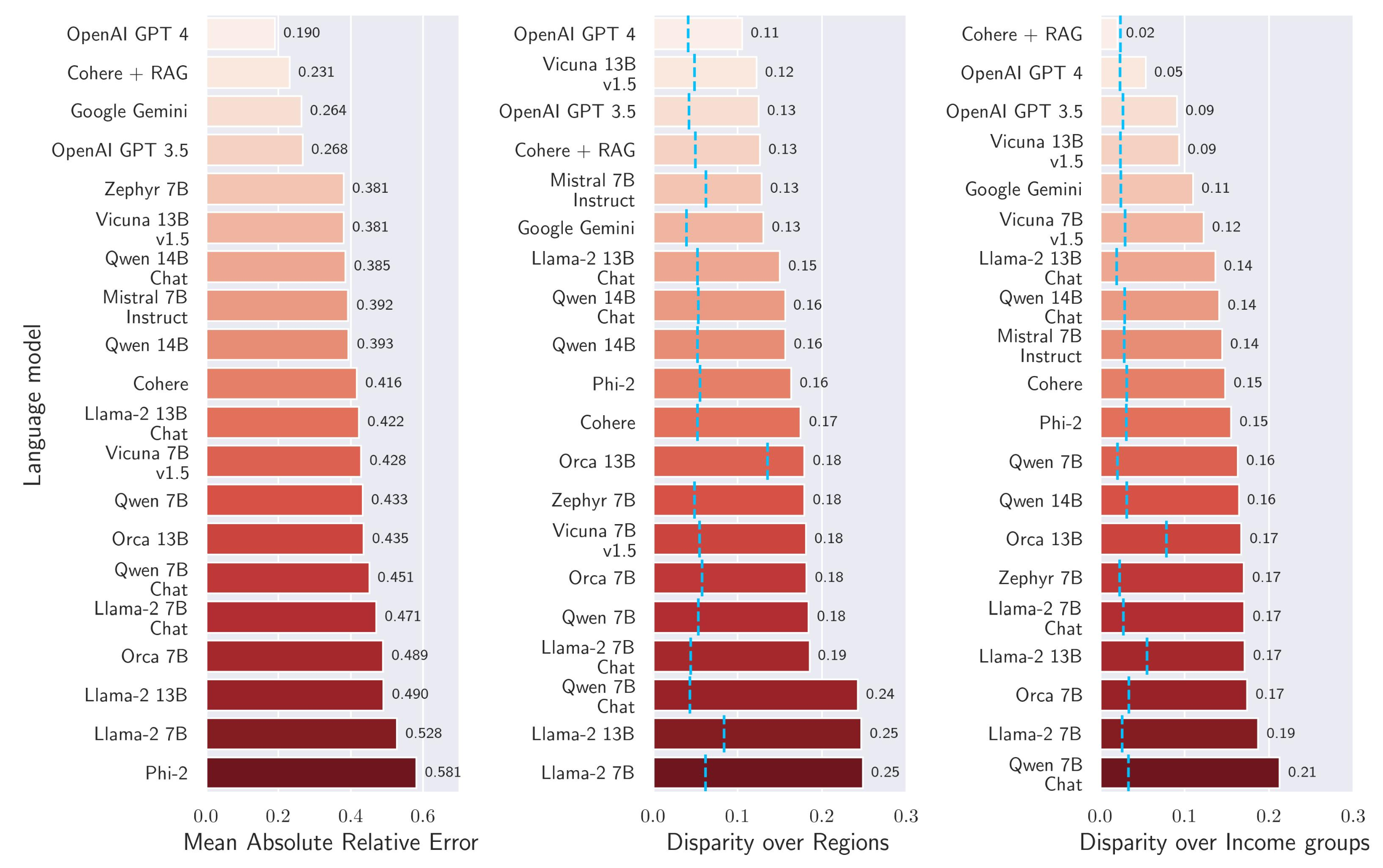
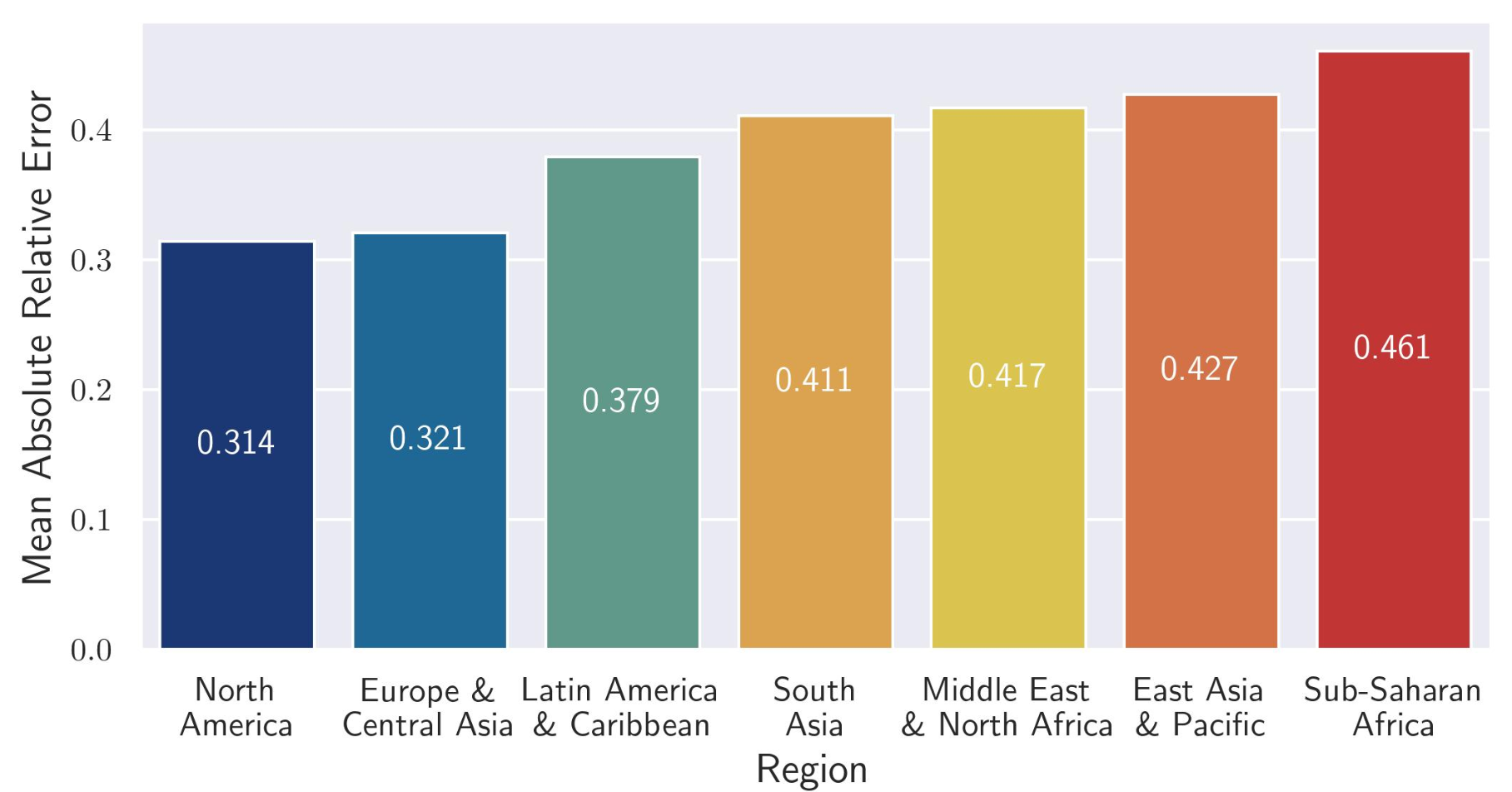
This is a second post on the recent study by Moaryeri et al. on bias in LLMs when recalling factual country statistics. The article also breaks down the individual performance of 20 different models used. It provides an interesting baseline in which to examine model design and performance.
A recent study by Moaryeri et al. examines the geographic bias in LLMs when recalling factual country statistics. The research highlights significant disparities in data accuracy across different regions and income levels, emphasizing the need to address these biases for more equitable AI development. This initial look into the persistent North American and European bias offers valuable insights into the challenges of creating globally fair algorithms.