Geographic Bias in LLMs: A Global Challenge
#bias #geographic #socioeconomic #diversity #LLM #journalclub
In recent years, the rise of Large Language Models (LLMs) has revolutionized the way we process and retrieve information. These models, powered by vast amounts of data, have demonstrated remarkable capabilities in generating human-like text and providing us with information limited only by our imagination. However, a significant challenge persists: factual accuracy, especially on a global scale. A recent publication by Moaryeri et al. provides an initial look on this issue by evaluating the accuracy of 20 different LLMs in recalling 11 different country-specific statistics (e.g., population, GDP, and others found in World Bank data). The findings reveal an quantitative comparison in accuracy of LLMs across different regions and income levels.
A Snapshot of Geographic Bias
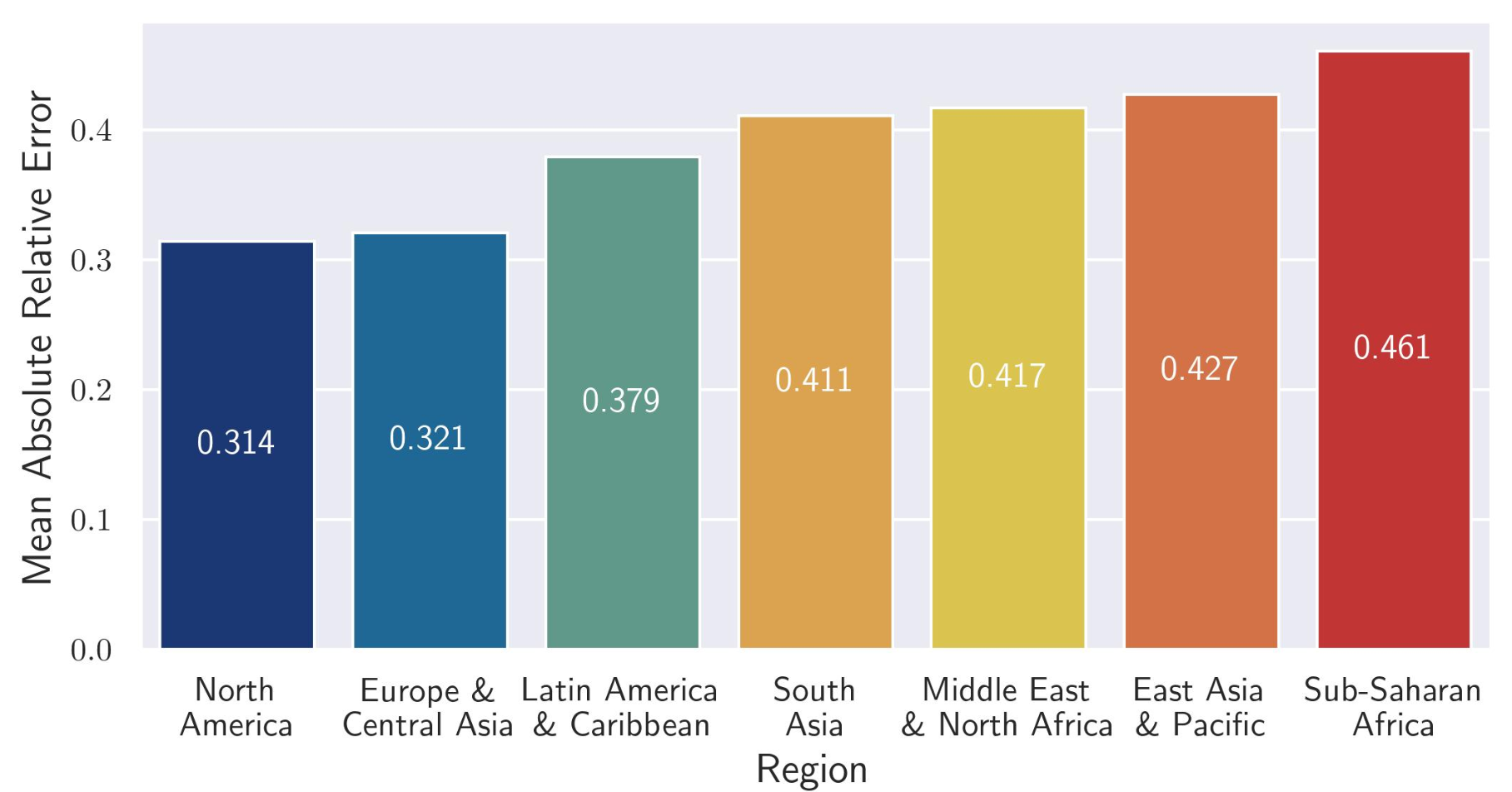
Moaryeri et al.'s research provides a critical assessment of LLM performance, highlighting the persistent struggle to create globally equitable algorithms. By examining how well these models recall factual data about various countries while using controlled and consistent prompts, the study offers a benchmark for measuring geographic bias. This article quantifies algorithm performance using Absolute Relative Error which is defined as \( \frac{|a - b|}{\max(a, b)} \), where a and b are LLM generated value and the ground truth value from World Bank data. When analyzing the data by region, we can see 50% higher error rates in data related to sub-Saharan Africa region compared to the North American region.
Income Levels and Data Accuracy
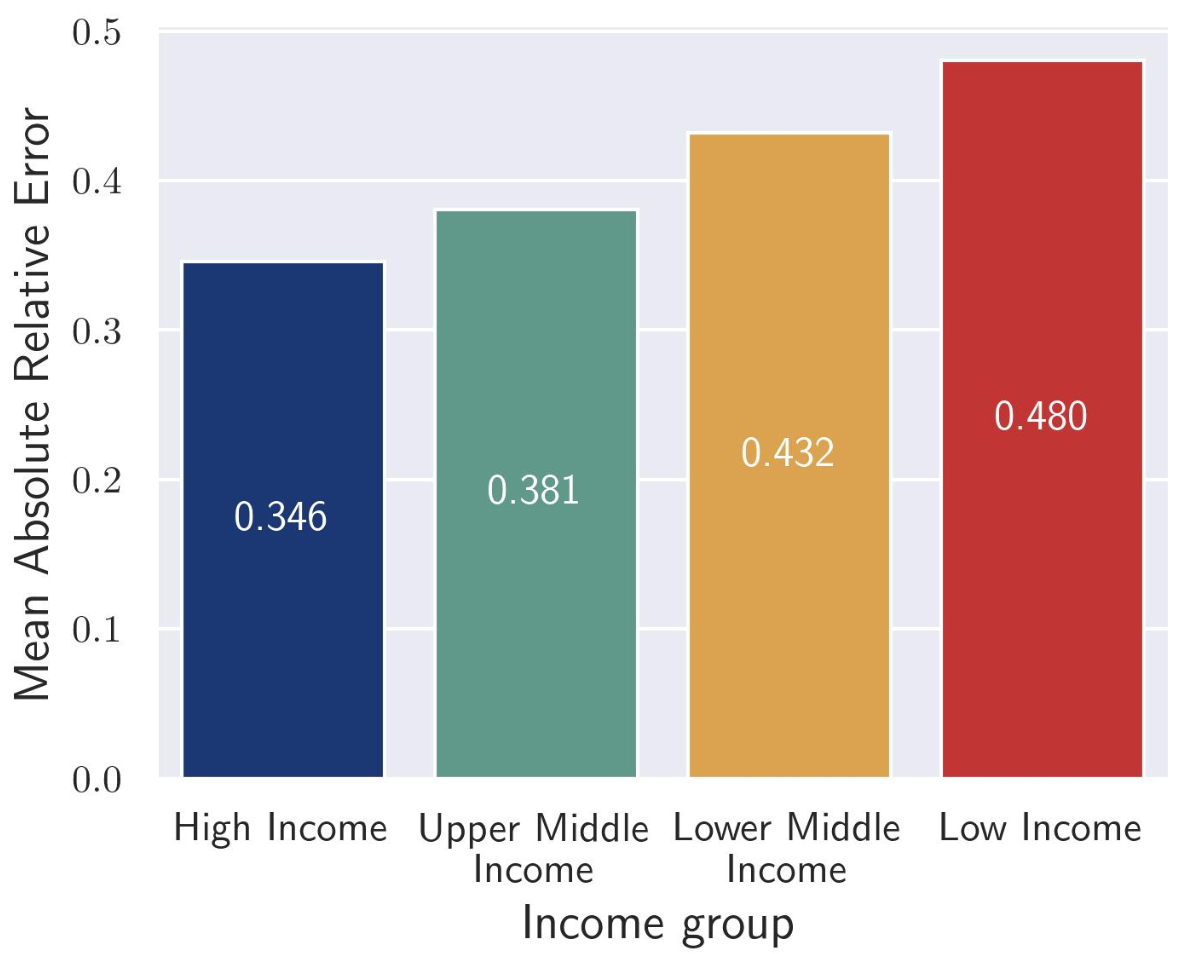
Similarly, when countries were reclassified into relative income groupings rather than regions, a similar result was observed. Although this is expected given the correlation between a country's region and its income level, the results underscore the need to consider the need to consider multiple types of classification when considering biases in LLM training and development.
Individual Country Analysis
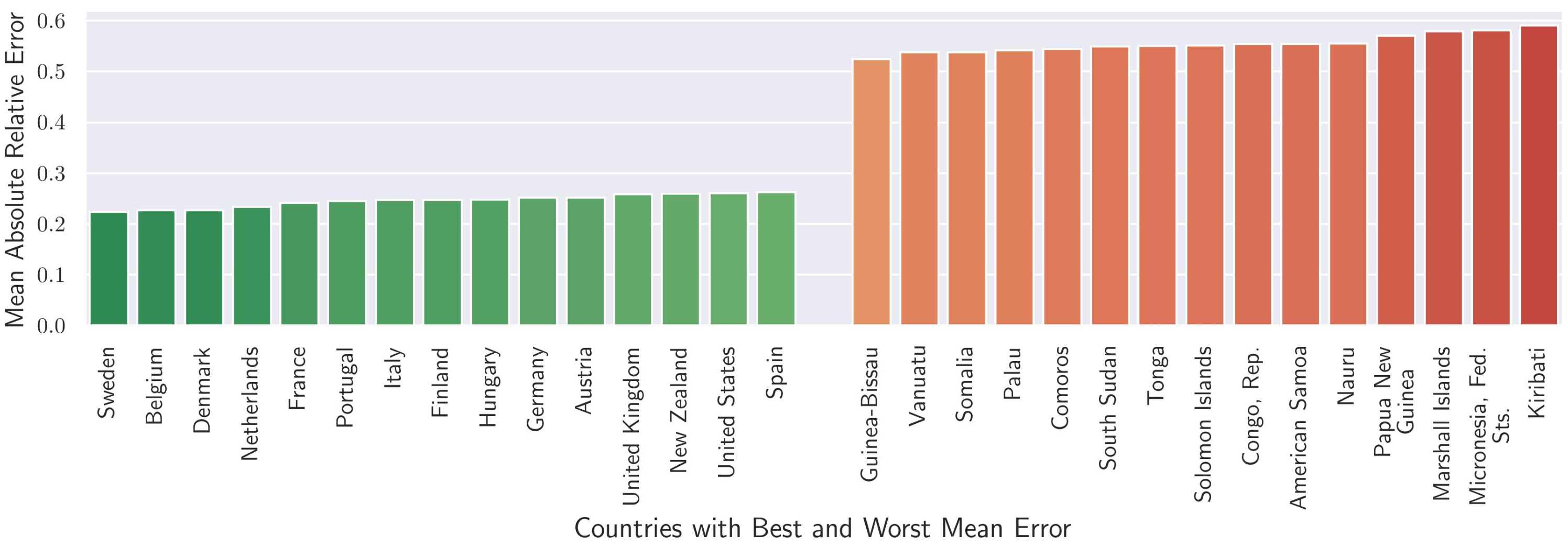
Delving deeper into the data, the disparity in LLM accuracy becomes even more pronounced when examining individual countries on a more anecdotal levels. Of the top 15 countries with the most accurate responses, all 15 belonged to the high-income group. Of the bottom 15 countries with the least accurate responses, all 15 belong to the low-income group.
Broader Implications and the Path Forward
The findings from this study have far-reaching implications, particularly as LLMs become more integrated into our daily lives and various sectors such as healthcare, education, and finance. Geographic and socioeconomic biases in these models can perpetuate existing inequalities, limiting access to accurate information for disadvantaged groups. Addressing these biases is crucial to ensuring that the benefits of AI are equitably distributed.
To mitigate these biases, several strategies must be employed. First, data collection efforts need to be more inclusive, ensuring diverse and representative datasets. This includes sourcing high-quality data from underrepresented regions. Second, model training practices should be refined to account for and correct biases. Advanced algorithms and techniques, such as fairness-aware machine learning, can help reduce the impact of biased data. Finally, transparency in the development and deployment of LLMs through sharing methodologies, datasets, and evaluation metrics fosters collaboration and drives progress towards more equitable AI.
In conclusion, as LLMs continue to evolve and permeate various aspects of society, addressing geographic and socioeconomic biases is not just a technical challenge but a moral imperative. By striving for fairness and inclusivity in AI, we can harness the full potential of these technologies to create a more equitable world. The journey towards bias-free AI is ongoing, and it requires collective effort, innovation, and a commitment to global fairness.