LLM Collapse from Self-Generated Data
#data #LLM #commentary
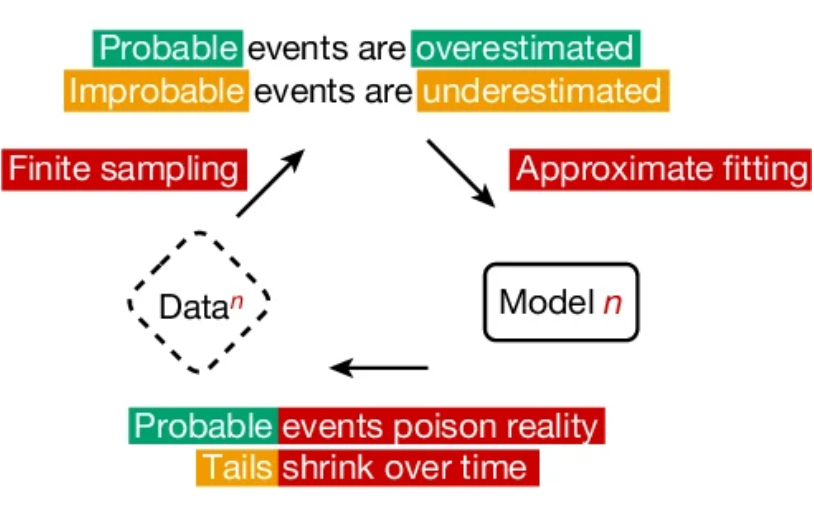
Model collapse is a potential issue for AI models that has gained attention in the research community. It occurs when models are repeatedly trained on data generated by other models, which can lead to a reduction in data diversity and an accumulation of errors, ultimately degrading performance and accuracy. A recent paper in Nature by Shumailov et al. delves into this phenomenon, providing valuable insights into the risks and mechanisms of model collapse.
Experimental Design
The authors of the study conducted experiments to cover a worst-case scenario: training models iteratively on synthetic copies of the original training data. While this scenario is not currently an issue in commercial-grade models, it serves as a thought experiment to explore the potential future where synthetic data might overwhelm real human-produced data.
The findings of Shumailov et al. highlight a key issue: a combination of finite sampling and inappropriate fitting leads to the overestimation of probable events and the underestimation of improbable events. This imbalance can distort the model's understanding of reality, causing it to prioritize common patterns while neglecting rarer, but potentially important, occurrences.

Mitigations
To mitigate the risk of model collapse, several strategies can be employed:
- Reinforcement Learning from Human Feedback (RLHF): Guiding models with human feedback ensures that the data remains relevant and accurately reflects human perspectives. This feedback loop helps in curating the data set and maintaining its quality over time.
- Data Enrichment: Incorporating diverse and high-quality data sources helps maintain the robustness of the training data set. By adding new human-generated data at each training stage, models can avoid the pitfalls of relying too heavily on synthetic data. This continuous integration of fresh data reduces the risk of missing important parts of the original data distribution.
- Quality Checks: Implementing rigorous quality control measures is crucial to detect and address potential issues in the data. Regular evaluation and adjustments ensure that the model does not deviate from its intended performance. This includes human evaluations and annotations, particularly in specific domains where precision is critical.
Current State
While early generation models relied solely on human-created data, commercial-grade AI models in recent years have increasingly incorporated synthetic data. This approach has enabled the creation of larger datasets and provided engineering teams with greater control over the input data. To date, there have been no widespread effects of model collapse from this increased synthetic data use, suggesting that the diversity and breadth of the data used are sufficient to avoid the issues highlighted in the paper.
Future Considerations
However, as the AI industry matures and the volume of synthetic data continues to grow, it remains to be seen whether model collapse will become more prevalent. There is a possibility that subtle issues may already exist, eventually reaching a critical mass that impacts model performance. Ongoing research and monitoring will be important in identifying and addressing these challenges to ensure the continued reliability and effectiveness of AI models.
The study by Shumailov et al. serves as an important reminder of the potential pitfalls in AI development and the need for careful management of training data. By understanding and mitigating the risks of model collapse, we can build more resilient and trustworthy AI systems for the future.