Expansive Landscape of LLM Training Data
#data #LLM #commentary
Large language models (LLMs) are renowned for their vast training datasets, but what exactly constitutes "large"? Are these models approaching the limits of available digitized text data?
Defining "Large" in LLM Training Data
While newer generation models have become more secretive about their inner workings due to competitive pressures, earlier models like OpenAI’s GPT-3 provide some insight. GPT-3, for instance, was trained on a data set with <1TB of text data. Much of this data comes from web scraping, particularly using datasets like Common Crawl.
Sources of Training Data
The IDC forecasts that the world will have produced 175 zetabytes (175,000,000,000 TB) of data by 2025. Irrespective of the accuracy of this forecast, most of that data is not available as training data. If we limit our analysis to the amount of data found on the web through web indexing such as Common Crawl, then we drop down to 9.5 petabytes (1000 TB). Even still, for LLMs, we are interested in relevant text data only. So instead of working top-down on this estimate, let's work from the bottom-up and look at relevant web data, books, and scholarly articles, while ignoring code repositories and social media content.
The Web
Data from the web can be accessed through web crawlers such as Common Crawl. While web crawlers do not index the entire web, they provide a rough estimate of the easily accessible web. According to crawler estimates, there are approximately 3 billion web pages currently indexed, as outlined in the estimate methodology. Assuming an average of 500 words per page and 6 bytes per word, this amounts to roughly 1.5 trillion words or 9TB of text data. Including historical web pages would significantly increase this figure to around 200 billion web pages, equating to about 100 trillion words or 600TB of text data. However, using historical data would involve substantial duplication due to the repetitive nature of web content over time.
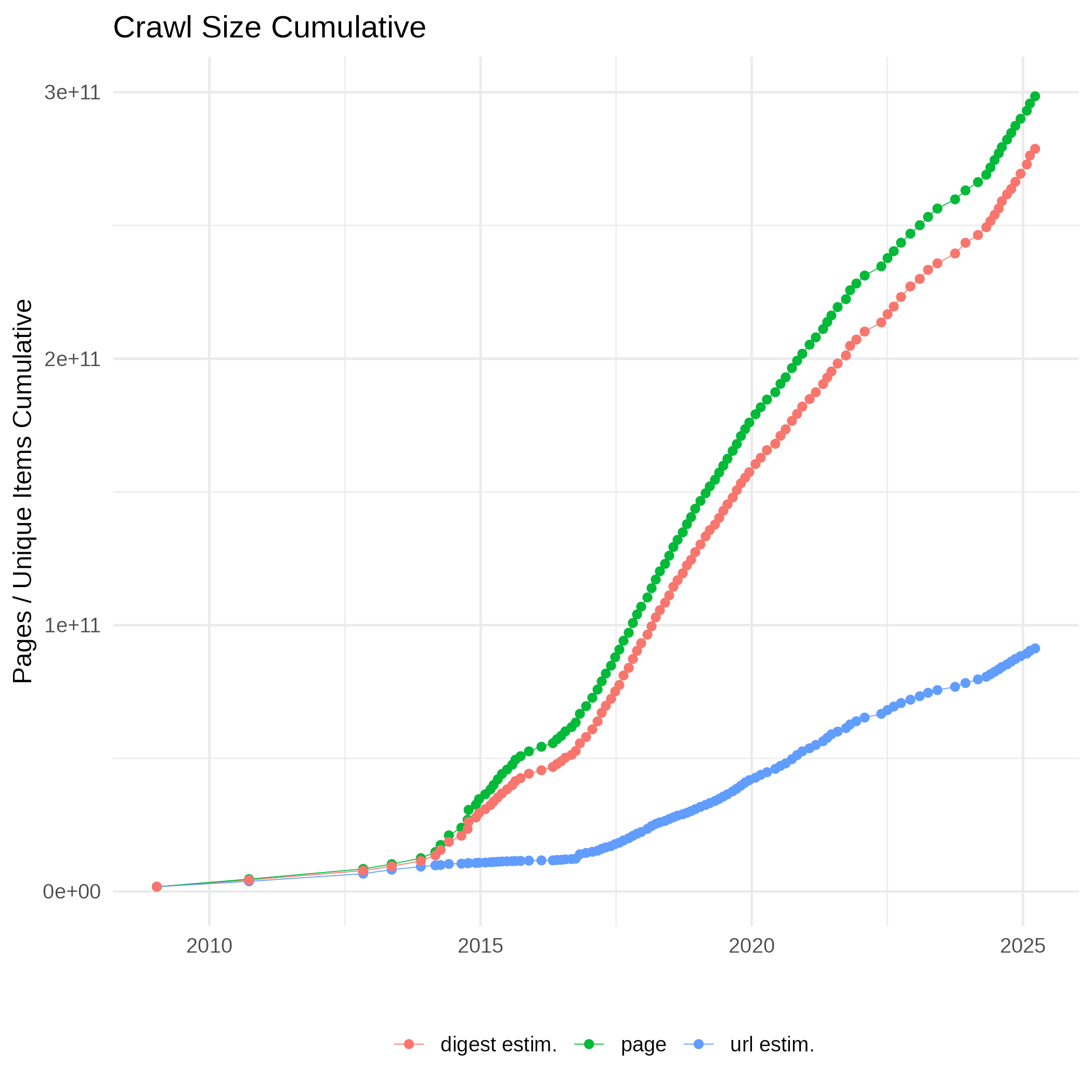{kind=link}

Books
There are around 40 million digitized books available today. With an average of 64,000 words per book and 6 bytes per word, this source alone provides about 2.5 trillion words, or 15TB of text data. Books offer a wealth of diverse, high-quality information spanning numerous genres and disciplines, making them invaluable for training LLMs.
Scholarly Articles
The world of academia contributes approximately 114 million scholarly articles. Averaging 6,000 words per article and 6 bytes per word, this results in about 0.6 trillion words, or 4TB of text data. Scholarly articles are rich in specialized knowledge and technical information, enhancing the depth and precision of LLM training datasets.
Summing It Up
Combining these conservative estimates, the total available text data from these sources amounts to about 30TB (9 + 15 + 4). Expanding our estimates to include a portion of code repositories, social media, non-indexed web pages, historical data, the total could easily reach a 2+ more orders of magnitude (let's say 3000TB conservatively).
Therefore, models in the ChatGPT-3 generation are utilizing 0.03-3.0% of the data available today with training sets ~1 TB.
However, model performance is based on more than just the size of the data, it is also about the data quality. We will look more into the well-known saying "garbage in, garbage out" in the next post.